
Amazon Textractは印刷されたテキスト、手書きの文字、およびデータをすべてのドキュメントから自動的に抽出します。
記事作成時現在、アジアパシフィック (東京)、アジアパシフィック (大阪)に対応していません。当然日本語にも対応していません。
そこで、日本語の画像を実際に読み取らせてみたらどうなるか試してみました。
リージョンは「オレゴン」を選択します。
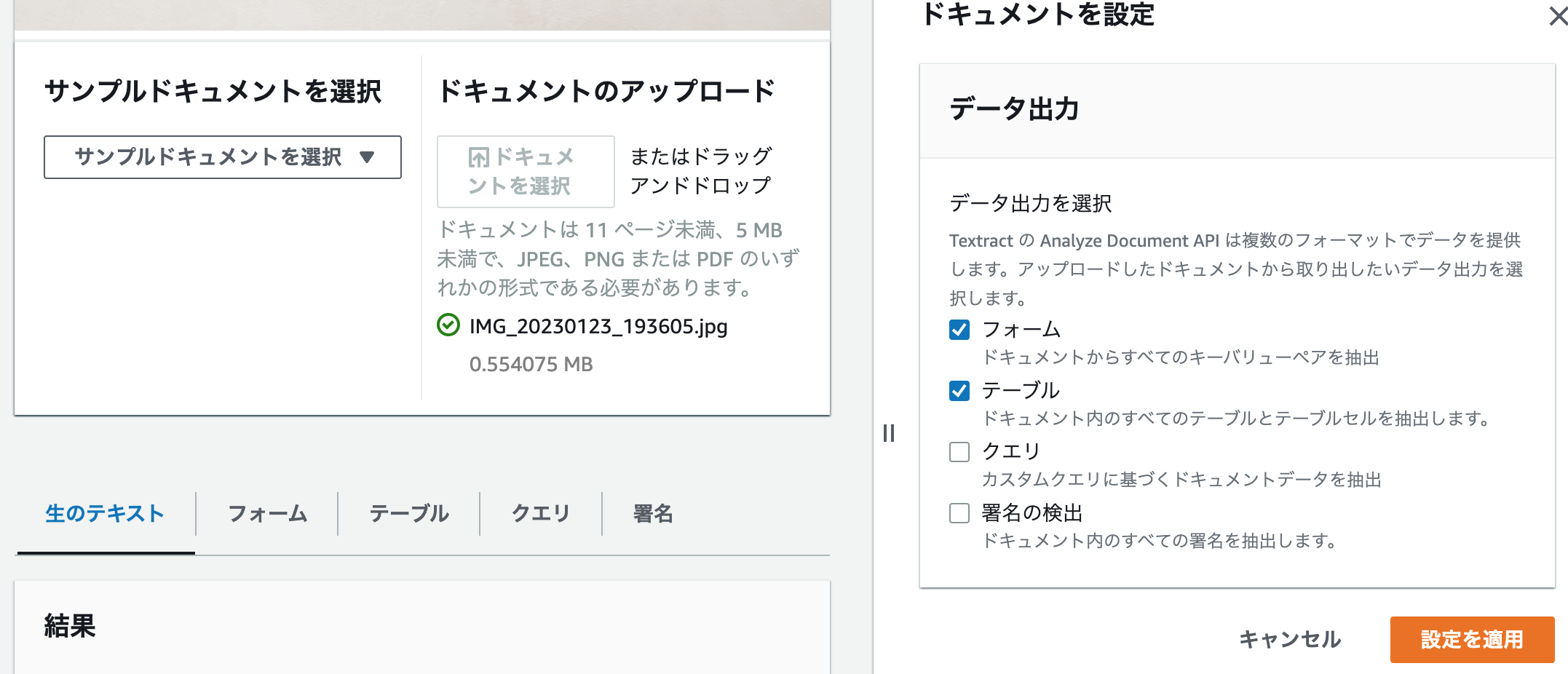
ドキュメントをアップロードし、データ出力を選択肢、設定を適用すると抽出が開始されます。
以下結果です。日本語はほとんど無視され、解析されませんでしたがごく一部解析されました。

解析結果をダウンロードして確認すると、日本語部分は謎のアルファベット、数字になってました。

日本語に対応してくれる日を心待ちにしたいと思います。

